Shardz
Fri, Dec 3, 2021Shard coordination has been one of the bigger challenges to design sharded systems especially for engineers with little experience in the subject. Companies like Facebook have been using general purpose shard coordinators, e.g. Shard Manager, and suggesting that general purpose sharding policies have been widely successful. A general purpose sharding coordinator is not a solution to all advanced sharding needs, but a starting point for average use cases. It’s a framework to think about core abstractions in sharded systems and providing a protocol that orchestrate sharding decisions. In the last few weeks, I’ve been working on an extendible general purpose shard coordinator, Shardz. In this article, I will explain the main concepts and the future work.
Sharding
Sharding is a concept of sharding load to different nodes in a cluster to horizontally scale systems. We can talk about two commonly used approaches to sharding strategies.
Hashing
Hashing is used to map an arbitrary key to a node in a cluster. Keys and hash functions are chosen carefully for load balancing to be effective. With this approach, each incoming key is hashed and its modulo is calculated to associate the key with one of the available nodes. Then, the request is routed to that node to be served.
hash_function(key) % len(nodes)
This approach, even though its shortcomings, offer an easy to implement way of designating a location to the incoming key. Consistent hashing can improve the excessive migration of shards upon node failure or addition. This approach is still commonly used in databases, key/value caches, and web/RPC servers.
One of the significant shortcomings of hashing is that the destination node is determined when handling an incoming request. The nodes in the system don’t know which shards they are serving in advance unless they can calculate the key ranges they need to serve. This situation makes it hard for nodes to preload data or it makes it harder to implement strict replication policies. The other difficulty is that existing shards cannot be easily visualized for debugging purposes unless you can query where key ranges live.
Lookup tables
An alternative to hashing is to generate lookup tables. In this approach, you keep track of available nodes and partitions you want to serve. Lookup tables are regenerated each time a node or a partition is added or removed, and is the source of the truth which node a partition should be served at. Lookup tables can also help enforcing replication policies, e.g. ensure there are at least two replicas being served at different nodes.
Lookup tables are generally easy to implement when you have homogenous nodes. In heterogenous cases, node capacity can be used to influence the distribution of partitions. Shardz chose to only tackle the homogenous nodes for now but it’s trivial to advance the coordinator to consider nodes with different capacity in the future.
P x N
Sharding with lookup tables is essentially a P x N problem where you have P partitions and N nodes. The goal is to distribute P partitions on the available nodes at any time. Most systems require replication for fault tolerance, so we decided to identify a P with a unique identifier and its replica number. At any times, a P should be replicated on Ns based on how many replicas are required.
type P struct { ID string, Replica int }
type N struct { Host string }

We expect users to manage partitions separately and talk to the Shardz coordinator to schedule them on the available nodes. The partitions should be uniquely identified within the same coordinator.
Sharder
A core concept in Shardz is the Sharder interface. A sharder allows users to register/unregister Ps and Ns. Then, users can query where a partition is being served. Sharder interface can be implemented with hashing or lookup tables. We don’t enforce any implementation details but expect the following interface to be satisfied.
type Sharder interface {
RegisterNodes(n ...N) error
UnregisterNodes(n ...N) error
RegisterPartitions(ids ...string) error
UnregisterPartitions(ids ...string) error
Partitions(n N) ([]P, error)
Nodes(partitionID string) ([]N, error)
}
Sharders can be extended to satisfy custom needs such as implementing custom replication policies, scheduling replicas in different availability zones, finding the correct VM type/size to schedule the partition.
Work stealing replica sharder
Shardz comes with general use Sharder implementations. The default sharder is a work stealing sharder that enforce a minimum number of replicas for each partition. ReplicaSharder implements a trivial approach to find the next available node by looking at the least overloaded node that doesn’t already serve a replica of the partition. If this approach fails, we will look for the first node that doesn’t already serve a replica of the partition. If everything fails, we pick a random node and schedule the partition on it.
func nextNode(p P) {
// Find the node with the lowest load.
// If the node is not already serving p.ID, return the node.
// Find all the available nodes.
// Randomly loop for a while until you find a node
// that doesn't serve p.ID (a replica).
// Return the node if something is found in acceptable number of iterations.
// Randomly pick a node and return.
}
Additional to the partition positioning, work stealing is triggered when a new node joins or a partition is unregistered. Work stealing can be triggered as many as times possible, e.g. routinely to avoid unbalanced load on nodes.
func stealWork() {
// Calculate the average load on nodes.
// Find nodes with 1.3x more load than average.
// Calculate how many partitions need to be removed
// from the overloaded node. Remove the partitions.
// For each removed partition, call nextNode to find
// a new node to serve the partition.
}
Protocol
Shardz have been heavily influenced by Shard Manager when it comes to making it easier for servers to report their status and coordinate with the manager.
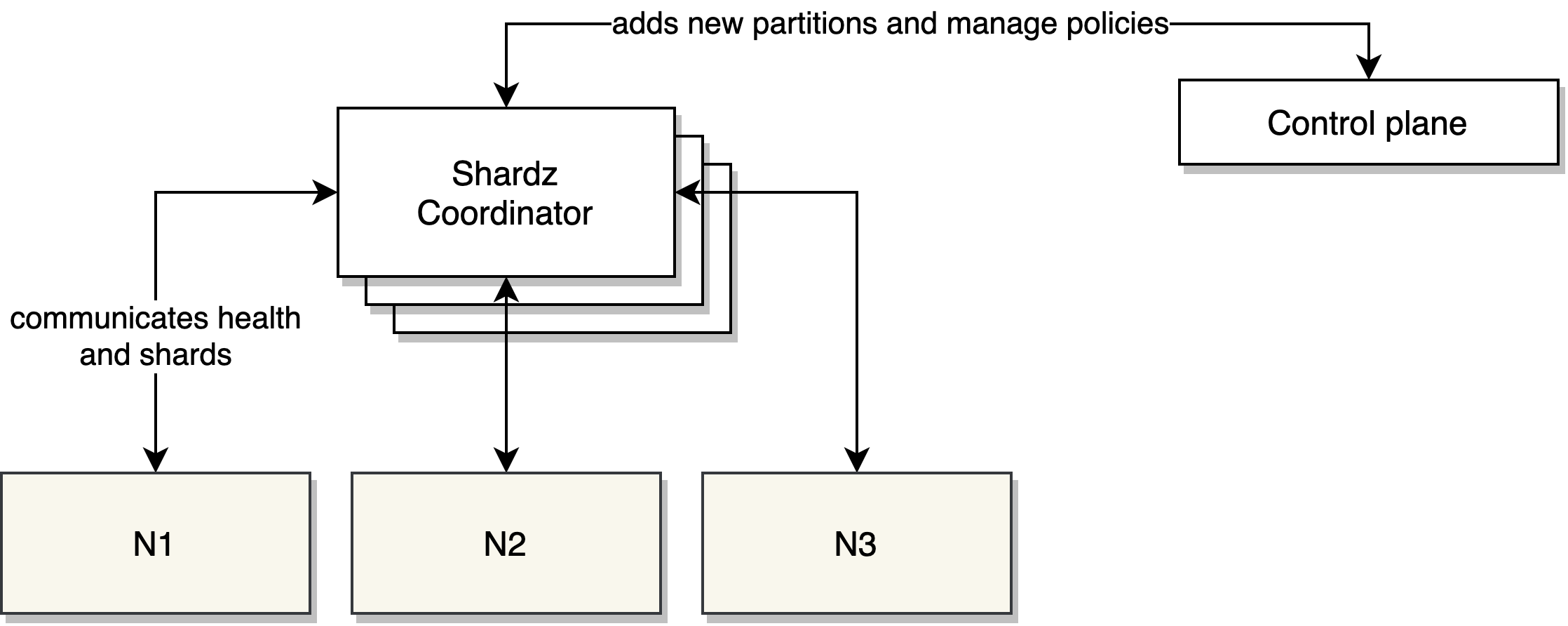
A worker node creates a server that implements the protocol. ServeFn and DeleteFn are the hooks when coordinator notifies the worker which partitions it should serve or stop serving.
import "shardz"
server, err := shardz.NewServer(shardz.ServerConfig{
Manager: "shardz.coordinator.local:7557", // shardz coordinator endpoint
Node: "worker-node1.local:9090",
ServeFn: func(partition string) {
// Do work to serve partition.
},
DeleteFn: func(partition string) {
// Do work to stop serving partition.
},
})
if err != nil {
log.Fatal(err)
}
http.HandleFunc("/shardz", server.Handler)
log.Fatal(http.ListenAndServe(listen, nil))
At startup, worker node automatically pings the coordinator to register itself. Then Shardz coordinator will ping the worker back periodically to check its status. The partitions that need to be served by the worker is periodically distributed and the ServeFn and DeleteFn functions are triggered automatically if partitions changed.
At a graceful shutdown, worker node automatically reports that it’s going away and give the coordinator a change to redistribute its partitions.
Fault tolerance
Shardz is designed to run in a clustered mode where there will be multiple replicas of the coordinator at any time. The coordinator will have a single leader that is responsible for sharding decision and propagating them to others. If leader goes away, another replica becomes the leader. ZooKeeper is used to coordinate the Shardz coordinators.
Future work
Shardz is still in the early stages but it’s a promising concept to build a reusable multi purpose sharding coordinator. It has potential to lower to entry barrier to design sharded systems. The next steps for the project:
- Fault tolerance. The coordinator still has work to be finished when running in the cluster mode.
- New Sharder implementations. Project aims to provide multiple implementation with different policies to meet the needs. I desire to open source this project to allow community to contribute.
- Language support for protocol implementation. We only have support for Go and should expand the server implementation to capture more languages to make it easy just to import a library to add Shardz support to any process.
- Visualization and management tools. Dashboards and custom control planes to monitor, debug and manage shards.
- An ecosystem that speaks Shardz. It’s an ambitious goal but a unified control plane for shard management would benefit the entire industry.